PhD Research in Multi-View Stereo
This page discusses the work undertaken during my PhD supervised by Roberto Cipolla under the guidance of George Vogiatzis and Carlos Hernández in the Department of Engineering at the University of Cambridge and Toshiba Research.
Introduction
Vision is a process that produces from images of the external world a description that is useful to the viewer and not cluttered with irrelevant information. [David Marr, Vision, 1982]
As proposed by Marr, one of the subject’s early pioneers, computer vision addresses the problem of inferring useful information from images and videos of the world around us. A statement such as this gives rise to a plethora of questions as we attempt to delve deeper into the aims and motivations of the study of vision. Principally among these might be the question of what do we mean by useful information. Over the intervening years researchers have proposed a variety of tasks that a vision system, whether human or machine, might wish to perform and each task has corresponding requirements on particular pieces of information that may prove useful. At the broadest level these tasks include:
- Recovering the stucture of the observed scene. This includes forming an understanding of the 3D world from visual observations, including an analysis of its physical shape and the motions of the viewer and the scene.
- Interpreting the contents of the observed scene. This includes the tasks of discovering the presence of objects and identifying them in a hierarchy, i.e. from classes of object down to specific instances.
The first of these tasks forms the area of interest for my research, in particular the goal of understanding and recovering the shape of the 3D world from visual information.
Motivation
Motivation for research in this area may be provided on two levels. Early investigations into vision attempted to break down biological systems into their constituent parts and hence build a model for the process as a whole. This approach broke down due to the complexity of the systems and the lack of understanding of the information processing tasks being performed; endeavouring to understand a particular implementation (the human visual system) without understanding the underlying principles involved. The insight offered by Marr and his contemporaries was the suggestion that: “One cannot understand what seeing is and how it works unless one understands the underlying information processing tasks being solved.” [Marr 1982]. Thus, the first motivation to study computer vision is to gain an insight into the fundamentals of information processing in vision. This in turn provides insights into questions about the human visual system and the portions of the brain that perform the corresponding interpretations.
| Computational Theory | What is the goal of the computation, why is it appropriate and what is the logic of the strategy by which it can be carried out? | |
| Representation and Algorithm | How can this computational theory be implemented? In particular what is the representation for the input and the output and what is the algorithm for the transformation? | |
| Hardware Implementation | How can the representation and algorithm be realised physically? |
Marr proposed three distinct levels, given above, upon which an information processing task must be understood. Thus we may conclude that the study of the computational theory, representation and algorithms involved in vision gives us an insight into its challenges and allows us to obtain a deeper understanding whether it be in the context of human or machine vision.
Applications
Besides intellectual curiosity, from the viewpoint of an engineer there is a strong motivation for understanding vision in order to create technologies which may useful in their own right. Currently there is a great demand for 3D models of objects in the world; in particular we are noticing the appearance of new 3D display technologies which will create the visualisations and interfaces of the future and change the way we are able to access and interpret information held on computers. Computer vision offers the possibility of providing this 3D information for many applications that in turn provide their own motivation. The most significant current and future applications of 3D model acquisition include:
The ability to generate 3D models from photos alone is highly attractive to museums and other archival institutions. Photographs are routinely taken for documentation in museums so for very little extra expense we may obtain high resolution models. These models allow interested parties to view pieces from any angle, in an interactive setting, from their own computers and allow museums to provide displays for all the pieces in their collections, not just the ones they have space to display. This is also particularly important for items which must be preserved in a restrictive environment that makes physical display or viewing difficult. Figure 1 shows an example of a model produced for the Victoria and Albert Museum.

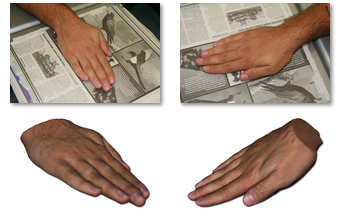
There have been many advances in medical imaging technologies for studying the internal features of the body but there are situations where a cheap method for creating models of the external body could be put to good use. For instance we can remove the need to take plaster casts in order to generate masks for radiotherapy or a brace for orthopaedics by obtaining a 3D model of part of the body from a small number of photographs. Figure 2 demonstrates a simple example: a model of a hand obtained using nothing more that a camera and a newspaper.
The entertainment industries are a huge source of demand for 3D data for film and television or providing interactive experiences in training simulations and games. This demand will only increase with the prevalence of new 3D display technologies that are already available in cinemas and in the home. As the ease of communication found with the internet is encouraging global collaboration, we face a greater demand for technologies for communication to reduce the need for travel and allow people to collaborate in an interactive setting. Systems to capture 3D content in real time will greatly increase the quality of this experience and allow the technology to blend into the background making communication more natural. We might also like to create our own 3D content in the home: Figure 3 shows a model of a sculpture, which was obtained from 8 photos taken with a compact digital camera. The processing was performed automatically and required no technical knowledge on the part of the user.

The ability to capture accurate 3D models is very useful internally to the scientific and engineering communities. An example would be structural analysis of buildings, providing verification of design and looking for wear and fatigue. The ability to perform accurate physical simulations during modern design processes creates a demand for models of existing infrastructure to improve the designs of the future, for example fluid flows around aircraft or buildings, or to assess and protect against earthquakes and hurricanes.
A common factor of these applications is the desire to reconstruct models from photos taken in the ‘real world’, away from the controlled conditions of the laboratory, and the recognition that the end users of these technologies are specialists in their own fields and not experts in computer vision. It is the desire to study vision whilst also making the outputs of this research useful to and usable by the people who may benefit from these technologies that motivates the contributions of my research.
Why is Vision Challenging?
The human visual system has little problem performing the tasks of recovering structure and interpreting scenes around us and this would lead us to assume that the task should be a relatively simple one for a computer. In fact this was the assumption, or perhaps optimism, of the early computer vision researchers who estimated time frames in the order of months for visual reconstruction tasks. We have yet to produce a fully automated visual system over the intervening years, however we have attained a much greater understanding of the problems involved and are able to explain how complex and challenging the task actually is.
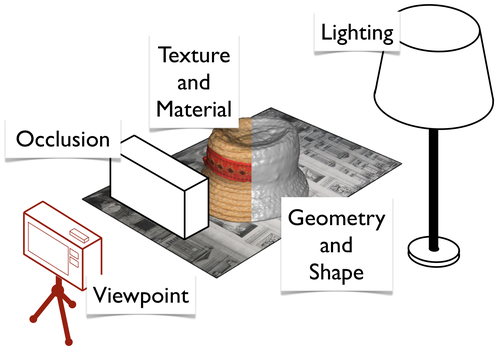
Figure 4 portrays the principal parameters that combine to make up the 2D image captured, at an instant in time, by a photo. Here we have neglected the evolution of time and thus have made an assumption of rigidity, that nothing moves or deforms, which in turn has already greatly simplified the problem. The probability theorist Jaynes remarked that “seeing is inference from incomplete information.” [Jaynes 2003], a statement that cuts to the heart of the problem. The combination of all of these complicated factors followed by projection onto a single 2D image plane results in a huge loss of information. When presented with the image alone it is no longer possible to measure any of the aforementioned parameters directly, instead we are left with ambiguities, which at best may place constraints on some of these factors.
The loss of information during image formation may be best illustrated by an example. If we consider a red part of an image then we may place constraints on the possible lighting and texture/colour of the object observed but we cannot measure directly whether a white object is being illuminated by a red light or a red object by a white light. The challenge of recovering 3D shape is then to infer an estimate of the geometry of the object in question such that it would generate the images observed under the same remaining parameters of viewpoint, lighting, material, texture and occlusion.
The study of computer vision looks to attempt the inversion of the imaging process by studying the constraints on the interplay of the factors that make up an image and then to generate (either explicitly or in a learning framework) cues and priors which may be combined with image measurements to resolve the information loss and thus the ambiguities. For example, a general scene has a very high dimensionality in terms of the freedom in geometry and reflectance, so there will be insufficient information to estimate these values without strong priors on both the object shape and the surface reflectance. The study of different scene representations and the establishment of techniques which enforce different assumptions lies at the heart of 3D computer vision research.
My Research
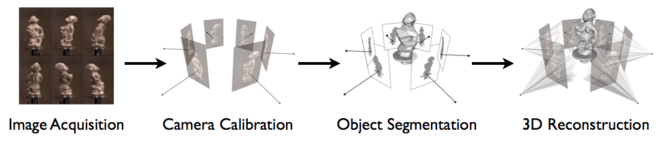
The reconstruction of 3D objects is an active topic of study for the computer vision community and recently there has been a growing interest in the subject, particularly in the development of ‘dense multi-view stereo’ reconstruction techniques [Seitz et al. 2006]. These techniques focus on producing 3D models from a sequence of calibrated images of an object. Figure 5 provides an overview of the pipeline of such processes.
Many existing reconstruction algorithms share one or more of the following constraints:
- Images are acquired in calibrated rigs or using other specialist equipment such as turntables.
- Large numbers of images are required.
- Images are taken against simple or known backgrounds to provide object silhouettes.
- A degree of specialist user interaction is required, either to control the algorithm during reconstruction or to perform preparatory work on the system input.
So far, the goal of our research has been to to extend existing algorithms and develop new approaches to overcome these limitations which, in turn, should serve to increase the applications of reconstruction techniques as well as making them more accessible to wider audiences. Towards this end we offer the following contributions:
- An undemanding and automatic method for camera calibration.
The calibration of a set of images involves determining a common set of parameter values as well as the position and orientation of the camera for each of the photos taken. Our contribution to this topic is to present an algorithm that requires no input from the user other than the images themselves and a planar surface, such as the newspaper in Figure 6, which presents a very easy process for the user. - An automatic segmentation system for image sequences.
Many of the existing reconstruction techniques require large numbers of calibrated images and the silhouette of the object in each image to obtain high accuracy reconstructions. Unfortunately, images taken outside of the laboratory will often observe the object against a cluttered background, for example compare the images in Figures 7(a). In this situation, the object must be separated from the background (segmented) manually, representing a sizeable task. Our contribution is an automatic segmentation algorithm for whole image sequences [Campbell et al. 2007, 2010]. Figure 7(b) provides some typical results. - An automatic algorithm for accurate reconstruction from a sparse set of images.
Current state-of-the-art algorithms will recovery accurate 3D shape when provided with large numbers of images (50-100) but under sparse data-sets (10-20 images) they lose accuracy. In order to address this we have introduced a new depth estimation process [Campbell et al. 2008] and shown that, by removing erroneous depth estimates at the start of the algorithm, good performance can be maintained. Figure 8 provides an example of the improvement offered for a single depth-map computed from 3 images.


| (a) | (b) |

| (a) | (b) | (c) | (d) |
All these algorithms are intended to operate on images captured on standard digital cameras and the processing is performed automatically. This means that the system may be used without any need for computer vision training or knowledge.
Publications
Neill D. F. Campbell, George Vogiatzis, Carlos Hernández and Roberto Cipolla,
European Conf. on Visual Media Production (CVMP), 2011
[pdf]
Neill D. F. Campbell, George Vogiatzis, Carlos Hernández and Roberto Cipolla,
Image and Vision Computing, vol. 28, no. 1, 2010
[pdf]
Neill D. F. Campbell, George Vogiatzis, Carlos Hernández and Roberto Cipolla,
European Conf. on Computer Vision (ECCV), 2008
[pdf]
Neill D. F. Campbell, George Vogiatzis, Carlos Hernández and Roberto Cipolla,
British Machine Vision Conf. (BMVC), 2007
[pdf]
References
[Jaynes 2003] E. T. Jaynes. Probability Theory: The Logic of Science. Cambridge University Press, 2003.
[Seitz et al. 2006] S. M. Seitz, B. Curless, J. Diebel, D. Scharstein, and R. Szeliski. A comparison and evaluation of multi-view stereo reconstruction algorithms. In Proc. IEEE Conf. on Computer Vision and Pattern Recognition, 2006.
[Hernández 2004] C. Hernández. Stereo and silhouette fusion for 3D object modeling from uncalibrated images under circular motion. PhD thesis, École Nationale Supérieure des Télécommunications, 2004.
[Hernández and Schmitt 2004] C. Hernández and F. Schmitt. Silhouette and stereo fusion for 3D object modelling. Computer Vision and Image Understanding, 2004.
[Strecha et al. 2008] C. Strecha, W. Von Hansen, L. Van Gool, P. Fua, and U. Thoennessen. On benchmarking camera calibration and multi-view stereo for high resolution imagery. In Proc. IEEE Conf. on Computer Vision and Pattern Recognition, 2008.